※ 김성훈 교수님의 [모두를 위한 딥러닝] 강의 정리
- 참고자료 : Andrew Ng's ML class
1) https://class.coursera.org/ml-003/lecture
2) http://holehouse.org/mlclass/ (note)
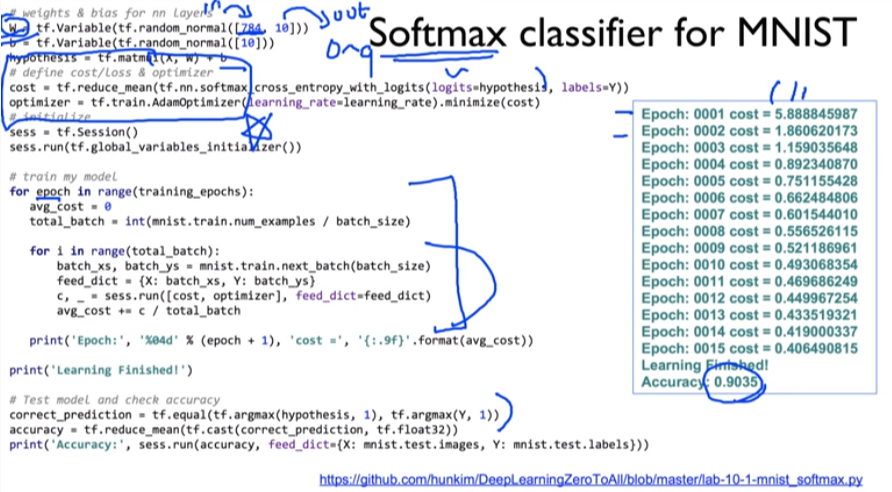
1. Softmax classifier for MNIST : Accuracy 0.9035
- (중요 코드)
| # weights & bias for softmax classifier |
| hypothesis = tf.matmul(X, W) + b |
| # define cost/loss & optimizer |
| cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=hypothesis, labels=Y)) |
| optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) |
2. NN for MNIST : Accuracy 0.9455
- (중요 코드) 3단으로 늘림, ReLU 사용
| # weights & bias for nn layers |
| W1 = tf.Variable(tf.random_normal([784, 256])) |
| b1 = tf.Variable(tf.random_normal([256])) |
| L1 = tf.nn.relu(tf.matmul(X, W1) + b1) |
| W2 = tf.Variable(tf.random_normal([256, 256])) |
| b2 = tf.Variable(tf.random_normal([256])) |
| L2 = tf.nn.relu(tf.matmul(L1, W2) + b2) |
| W3 = tf.Variable(tf.random_normal([256, 10])) |
| b3 = tf.Variable(tf.random_normal([10])) |
| hypothesis = tf.matmul(L2, W3) + b3 |
| # define cost/loss & optimizer |
| cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=hypothesis, labels=Y)) |
| optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) |

3. Xavier Initialization for MNIST (초기화를 잘 하기) : Accuracy 0.9779
- (중요 코드) 초기값 initializer만 변경
| # weights & bias for nn layers |
| # http://stackoverflow.com/questions/33640581/how-to-do-xavier-initialization-on-tensorflow |
| W1 = tf.get_variable("W1", shape=[784, 256], |
| initializer=tf.contrib.layers.xavier_initializer()) |
| b1 = tf.Variable(tf.random_normal([256])) |
| L1 = tf.nn.relu(tf.matmul(X, W1) + b1) |
| W2 = tf.get_variable("W2", shape=[256, 256], |
| initializer=tf.contrib.layers.xavier_initializer()) |
| b2 = tf.Variable(tf.random_normal([256])) |
| L2 = tf.nn.relu(tf.matmul(L1, W2) + b2) |
| W3 = tf.get_variable("W3", shape=[256, 10], |
| initializer=tf.contrib.layers.xavier_initializer()) |
| b3 = tf.Variable(tf.random_normal([10])) |
| hypothesis = tf.matmul(L2, W3) + b3 |

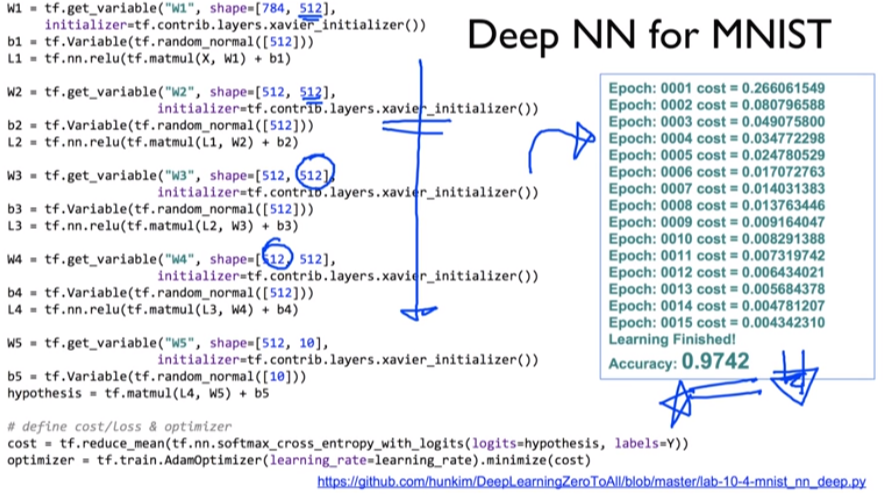
4. Deep NN for MNIST : Accuracy 0.9742
- (중요 코드) 5단으로 늘림, 더 넓힘. 깊고 넓게~ => but 결과는 실망 (아마도 overfitting)..
| # weights & bias for nn layers |
| # http://stackoverflow.com/questions/33640581/how-to-do-xavier-initialization-on-tensorflow |
| W1 = tf.get_variable("W1", shape=[784, 512], |
| initializer=tf.contrib.layers.xavier_initializer()) |
| b1 = tf.Variable(tf.random_normal([512])) |
| L1 = tf.nn.relu(tf.matmul(X, W1) + b1) |
| W2 = tf.get_variable("W2", shape=[512, 512], |
| initializer=tf.contrib.layers.xavier_initializer()) |
| b2 = tf.Variable(tf.random_normal([512])) |
| L2 = tf.nn.relu(tf.matmul(L1, W2) + b2) |
| W3 = tf.get_variable("W3", shape=[512, 512], |
| initializer=tf.contrib.layers.xavier_initializer()) |
| b3 = tf.Variable(tf.random_normal([512])) |
| L3 = tf.nn.relu(tf.matmul(L2, W3) + b3) |
| W4 = tf.get_variable("W4", shape=[512, 512], |
| initializer=tf.contrib.layers.xavier_initializer()) |
| b4 = tf.Variable(tf.random_normal([512])) |
| L4 = tf.nn.relu(tf.matmul(L3, W4) + b4) |
| W5 = tf.get_variable("W5", shape=[512, 10], |
| initializer=tf.contrib.layers.xavier_initializer()) |
| b5 = tf.Variable(tf.random_normal([10])) |
| hypothesis = tf.matmul(L4, W5) + b5 |
| # define cost/loss & optimizer |
| cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits( |
| logits=hypothesis, labels=Y)) |
| optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) |
5. Dropout for MNIST : Accuracy 0.9804
- (중요 코드) 1개의 layer 추가만으로 tensorflow에서 구현 가능. 통상 0.5~0.7로 training 후 1로 testing!
| W1 = tf.get_variable("W1", shape=[784, 512], initializer=tf.contrib.layers.xavier_initializer()) |
| b1 = tf.Variable(tf.random_normal([512])) |
| L1 = tf.nn.relu(tf.matmul(X, W1) + b1) |
| L1 = tf.nn.dropout(L1, keep_prob=keep_prob) |
...
| # train my model |
| for epoch in range(training_epochs): |
| avg_cost = 0 |
| for i in range(total_batch): |
| batch_xs, batch_ys = mnist.train.next_batch(batch_size) |
| feed_dict = {X: batch_xs, Y: batch_ys, keep_prob: 0.7} |
| c, _ = sess.run([cost, optimizer], feed_dict=feed_dict) |
| avg_cost += c / total_batch |
| print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost)) |
| print('Learning Finished!') |
| # Test model and check accuracy |
| correct_prediction = tf.equal(tf.argmax(hypothesis, 1), tf.argmax(Y, 1)) |
| accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) |
| print('Accuracy:', sess.run(accuracy, feed_dict={ |
| X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1})) |
6. Optimizers
- GradientDescentOptimizer 外 어떤 알고리즘이 더 좋은지 Simulation 가능
- http://www.denizyuret.com/2015/03/alec-radfords-animations-for.html
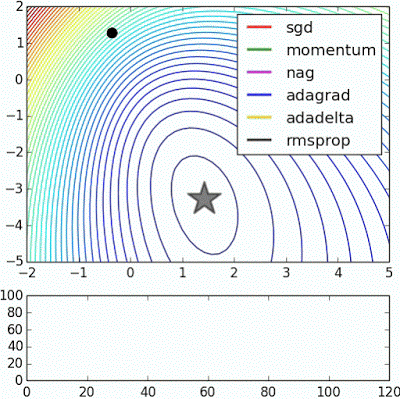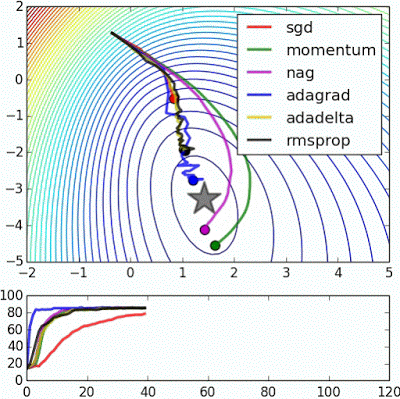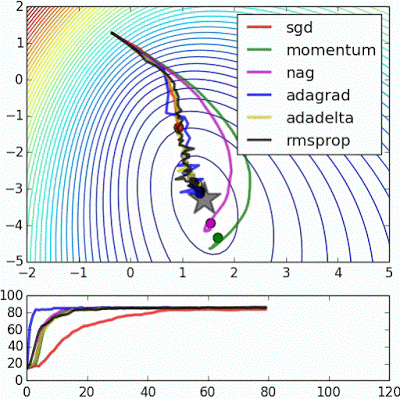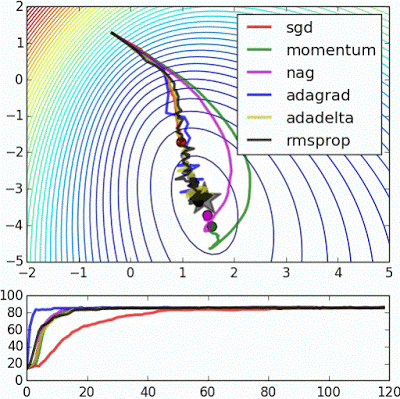
- Adam Optimizer를 처음 써보는 것을 추천 : 기존 코드에서 GradientDescentOptimizer -> AdamOptimizer로만 변경
| #define cost/loss & optimizer |
| cost =tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=hypothesis, labels=Y)) |
| optimizer =tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) |
'Deep Learning' 카테고리의 다른 글
| [머신러닝/딥러닝] Convolutional Neural Network(CNN) 활용사례 (0) | 2020.01.07 |
|---|---|
| [머신러닝/딥러닝] Convolutional Neural Network(CNN) (0) | 2020.01.03 |
| [머신러닝/딥러닝] Dropout & Ensemble (0) | 2020.01.03 |
| [머신러닝/딥러닝] Weight 초기화 잘해보자 (0) | 2020.01.02 |
| [머신러닝/딥러닝] Sigmoid << ReLU (0) | 2019.12.30 |



