※ 김성훈 교수님의 [모두를 위한 딥러닝] 강의 정리
- 참고자료 : Andrew Ng's ML class
1) https://class.coursera.org/ml-003/lecture
2) http://holehouse.org/mlclass/ (note)
1. Linear Regression
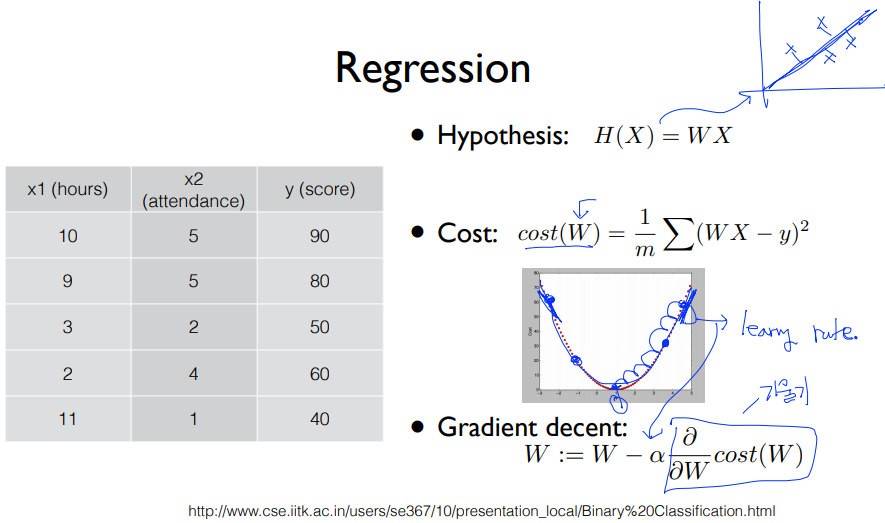
2. (binary) classification -> 0, 1 encoding
- Spam E-mail Detection: Spam(0) or Ham(1)
- Facebook feed: show(0) or hide(1)
- Credit Card Fraudulent Transaction detection: legitimate(0) or fraud(1)
3. Logistic Hypothesis
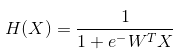
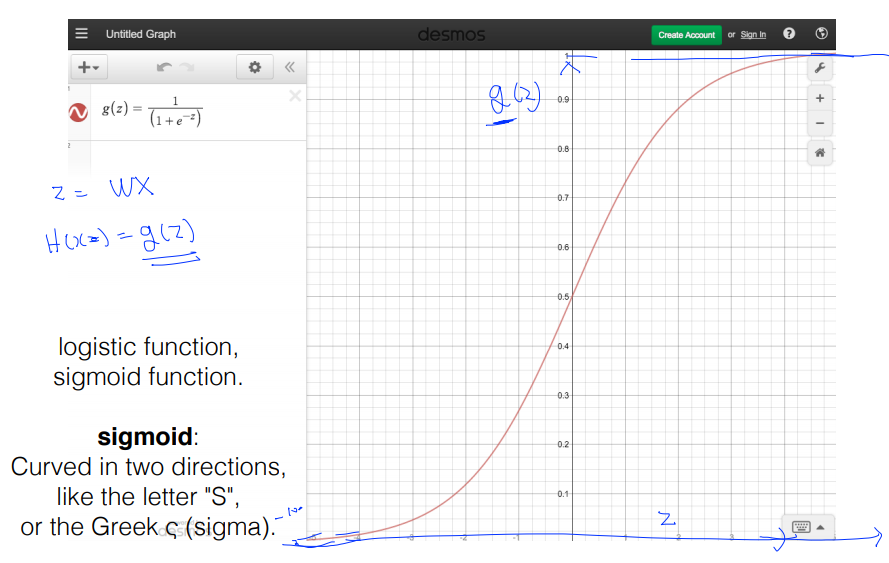
4. Logistic Regression의 새로운 cost 함수
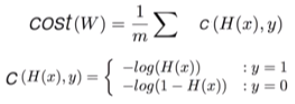
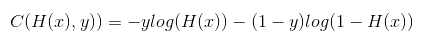
5. cost 함수의 최소화 - Gradient decent algorithm
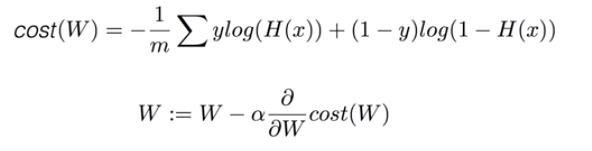
-> tensorflow
# cost function
cost = -tf.reduce_mean(-tf.reduce_sum(Y*tf.log(hypothesis) + (1-Y)*tf.log(1-hypothesis)))
# Minimize
a = tf.Variable(0.1) # Learnign rate, alpha
optimizer = tf.train.GradientDescentOptimizer(a)
train = optimizer.miminize(cost)
6. Tensorflow로 Logistic (regression) classifier 구현하기
(1) Training Data
| x_data = [[1, 2], [2, 3], [3, 1], [4, 3], [5, 3],[6, 2]] |
| y_data = [[0], [0], [0], [1], [1], [1]] |
| # placeholders for a tensor that will be always fed. |
| X = tf.placeholder(tf.float32, shape=[None, 2]) |
| Y = tf.placeholder(tf.float32, shape=[None, 1]) |
(2) tensorflow로 hypothesis 구현
| W = tf.Variable(tf.random_normal([2, 1]), name='weight') |
| b = tf.Variable(tf.random_normal([1]), name='bias') |
| # Hypothesis using sigmoid: tf.div(1., 1. + tf.exp(tf.matmul(X, W))) |
| hypothesis = tf.sigmoid(tf.matmul(X, W) + b) |
(3) tensorflow로 cost/loss function 구현
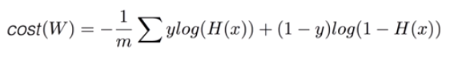
# cost function
cost = -tf.reduce_mean(-tf.reduce_sum(Y*tf.log(hypothesis) + (1-Y)*tf.log(1-hypothesis)))
(4) tensorflow로 cost 최소화 구현
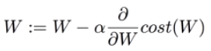
# Minimize
a = tf.Variable(0.01) # Learnign rate, alpha
optimizer = tf.train.GradientDescentOptimizer(a)
train = optimizer.miminize(cost)
(5) 예측 정확도 계산
| # Accuracy computation |
| # True if hypothesis>0.5 else False |
| predicted = tf.cast(hypothesis > 0.5, dtype=tf.float32) |
| accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32)) |
(6) Training the model
| # Launch graph |
| with tf.Session() as sess: |
| # Initialize TensorFlow variables |
| sess.run(tf.global_variables_initializer()) |
| for step in range(10001): |
| cost_val, _ = sess.run([cost, train], feed_dict={X: x_data, Y: y_data}) |
| if step % 200 == 0: |
| print(step, cost_val) |
(7) 예측 정확도 출력
| # Accuracy report |
| h, c, a = sess.run([hypothesis, predicted, accuracy], |
| feed_dict={X: x_data, Y: y_data}) |
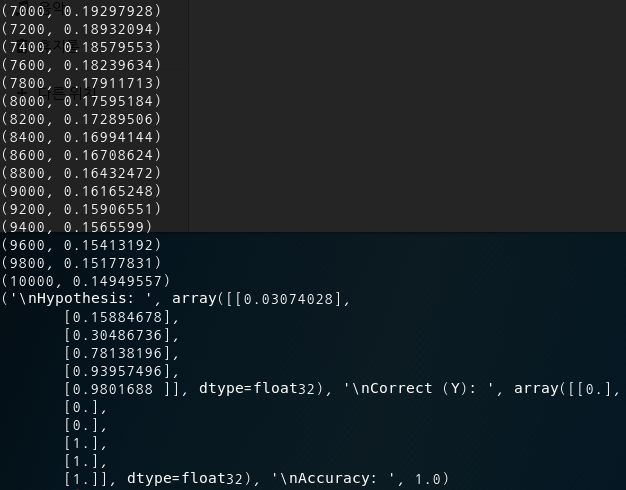
| print("\nHypothesis: ", h, "\nCorrect (Y): ", c, "\nAccuracy: ", a) |
(8) 실행결과 : 정확도 100% !!
7. 실제 데이터로 테스트
(1) diabetes.csv
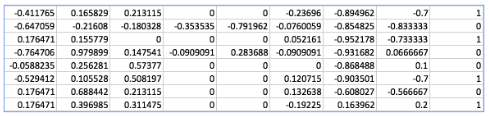
https://github.com/hunkim/DeepLearningZeroToAll/blob/master/data-03-diabetes.csv
hunkim/DeepLearningZeroToAll
TensorFlow Basic Tutorial Labs. Contribute to hunkim/DeepLearningZeroToAll development by creating an account on GitHub.
github.com
(2) tensorflow 구현
| # Lab 5 Logistic Regression Classifier |
| import tensorflow as tf |
| import numpy as np |
| tf.set_random_seed(777) # for reproducibility |
| xy = np.loadtxt('data-03-diabetes.csv', delimiter=',', dtype=np.float32) |
| x_data = xy[:, 0:-1] |
| y_data = xy[:, [-1]] |
| print(x_data.shape, y_data.shape) |
| # placeholders for a tensor that will be always fed. |
| X = tf.placeholder(tf.float32, shape=[None, 8]) |
| Y = tf.placeholder(tf.float32, shape=[None, 1]) |
| W = tf.Variable(tf.random_normal([8, 1]), name='weight') |
| b = tf.Variable(tf.random_normal([1]), name='bias') |
| # Hypothesis using sigmoid: tf.div(1., 1. + tf.exp(-tf.matmul(X, W))) |
| hypothesis = tf.sigmoid(tf.matmul(X, W) + b) |
| # cost/loss function |
| cost = -tf.reduce_mean(Y * tf.log(hypothesis) + (1 - Y) * |
| tf.log(1 - hypothesis)) |
| train = tf.train.GradientDescentOptimizer(learning_rate=0.01).minimize(cost) |
| # Accuracy computation |
| # True if hypothesis>0.5 else False |
| predicted = tf.cast(hypothesis > 0.5, dtype=tf.float32) |
| accuracy = tf.reduce_mean(tf.cast(tf.equal(predicted, Y), dtype=tf.float32)) |
| # Launch graph |
| with tf.Session() as sess: |
| # Initialize TensorFlow variables |
| sess.run(tf.global_variables_initializer()) |
| for step in range(10001): |
| cost_val, _ = sess.run([cost, train], feed_dict={X: x_data, Y: y_data}) |
| if step % 200 == 0: |
| print(step, cost_val) |
| # Accuracy report |
| h, c, a = sess.run([hypothesis, predicted, accuracy], |
| feed_dict={X: x_data, Y: y_data}) |
| print("\nHypothesis: ", h, "\nCorrect (Y): ", c, "\nAccuracy: ", a) |
(3) 실행결과
step, cost :
(0, 0.82793975)
(200, 0.75518084)
(400, 0.7263554)
(600, 0.70517904)
(800, 0.6866306)
(1000, 0.669853)
...
(9000, 0.49424884)
(9200, 0.49348038)
(9400, 0.49275032)
(9600, 0.49205625)
(9800, 0.49139577)
(10000, 0.4907668)
hypothesis :
[0.4434849 ],
[0.9153646 ],
[0.22591159],
[0.93583125],
[0.3376363 ],
[0.70926887],
[0.94409144],
...
correct(Y) :
[0.],
[1.],
[0.],
[1.],
[0.],
[1.],
[1.],
...
Accuracy :
0.7628459
'Deep Learning' 카테고리의 다른 글
| [머신러닝/딥러닝] 팁 : Learning rate, Preprocessing, Overfitting (0) | 2019.12.12 |
|---|---|
| [머신러닝/딥러닝] Softmax Classification 구현하기 by TensorfFlow (0) | 2019.12.11 |
| [머신러닝/딥러닝] 파일에서 Tensorflow로 데이터 읽어오기 (0) | 2019.12.02 |
| [머신러닝/딥러닝] multi-variable linear regression을 Tensorflow 구현 (0) | 2019.11.29 |
| [머신러닝/딥러닝] Linear Regression의 cost 최소화의 Tensorflow 구현 (0) | 2019.11.21 |
