사례4.
|
경찰청장은 음주운전 횟수에 따라 혈중 알코올 농도가 높아지면 현행보다 더 처벌을 강화하려고 도로교통법을 개정하려고 하고 있다. 교통과장은 음주운전자의 음주횟수에 따른 혈중 알코올 농도변화를 알아보기 위하여 음주횟수(1회, 2회, 3회)에 따라 각 10명씩을 뽑아 혈중 알코올 농도를 조사하여 경찰청장에게 보고하였다. 경찰청장은 음주운전 횟수가 많은 운전자를 더 강하게 처벌하는 도로교통법을 개정할 수 있는가? (90%신뢰수준에서 검증할 것.) |
- 분산분석을 이용한 검정 -
<문제의 소재>
음주운전 횟수가 증가할수록 혈중 알코올 농도가 증가하는지 여부를 판별하여 야 한다.
데이터의 경우, 음주횟수가 각각 1회, 2회, 3회로서, 집단 세 개로 나누어 질 수 있으므로, 해당 집단간 차이가 유의한지 분산분석(Analysis of variance : ANOVA)으로 확인하면 될 것이다.
종속변수인 혈중 알코올 농도(%)에 영향을 미치는 독립변수는 음주횟수(회) 1개이므로, 일원 분산 분석(one-way ANOVA)을 통 해 각 집단에 따라 혈중 알코올 농도의 차이가 있는지 알아보겠다.
<검정의 원리>
1. 분산분석의 의의
셋 이상의 집단들의 평균들이 서로 차이가 있는지를 검정할 때 이용되는 통계 방법을 분산분석이라고 한다. 분산분석은 주로 비계량적인 독립변수(명목척도)와 계량적인 종속변수(등간 혹은 비율 척도) 사이의 관계를 파악하는 데 이용된다.
분산 분석의 귀무가설은 집단들의 집단 평균값이 모두 동일하다는 것이며, 대립 가설은 집단 평균값이 동일하지 않다는 것이다. 여기서 주의할 것은 귀무가설에서 보는 바와 같이 분산 분석은 다수의 모집단 의 평균의 동일성 여부를 총괄적으로 검정하는 것이며, 개별적인 모집단의 평균 이나 두 모집단의 평균차를 검정하는 것이 아니라는 것이다.
2. 분산분석의 원리
분산분석은 독립변수에 의해 구분된 집단들이 동일한 집단인지 아닌지를 분산의 개념을 이용해 검정하는 통계적 분석 방법이다. 일반적으로 모든 실험은 여러 가지 요인들에 의해 영향을 받는데, 분산분석은 실험에서 관측된 변동량(문제 4의 경우, 혈중 알코올농도)을 분산의 개념으로 파악한 다음, 이러한 분산을 체계적 분산과 오차분산에 의한 부분으로 구분해 비교함으로써, 각 요인의 영향력 유무 에 관한 판단을 하는 것이다.
즉, 관측된 변동량은 요인간의 차이(처리 변동)과 우 연적인 변동(오차 변동)의 합이며, 전체분산은 집단 간 분산과 집단 내 분산의 합 이다. 분산분석에서는 가설의 검정을 위해 F 검정 통계량을 사용한다. F검정이란 집단 간의 차이가 있음을 검정하기 위해 집단 간 평균 분산을 집단 내 평균 분산으로 나눈 값이며, F 분포는 자유도값에 좌우된다.
분산 분석에서 집단 간 차이가 유의 하기 위해서는 (즉, 문제 4에서 음주횟수에 따라 혈중 알코올 농도의 차이가 있기 위해서는) 집단 내의 변이는 가능한 한 작아야 하고, 집단 간의 변이는 가능한 한 커야 한다.
3. 일원 분산 분석(one-way ANOVA)
독립변수의 개수가 1개인 경우 일원 분산 분석을 이용하므로, 문제 4의 경우 독립변수로서 음주운전횟수만을 가정하고 있으므로 이를 통해 파악이 가능하다.
문제 4의 경우, 집단을 나타내는 변수(분류 변수)인 음주운전횟수가 요인(factor) 혹은 인자(effects)가 되고, 음주운전횟수 1,2,3회는 분류 집단이 된다.
<문제의 해결>
귀무가설 : 음주횟수 1회, 2회, 3회 각각의 평균이 모두 같다.
대립가설 : 귀무가설 평균 중에서 적어도 두 모집단의 평균은 서로 같지 않다.
SPSS 통계 패키지를 이용해 일원 분산 분석을 실시하기 위해서는 독립변수와 종속변수가 하나이고, 독립변수는 명목수준, 종속 변수는 등간수준 이상이어야 한 다. 또한 표본이 정규성과 등분산성을 충족할 수 있어야 한다. 문제 4의 데이터는 전자의 조건을 만족하고 있으며, 후자의 조건을 충족하는지 검증할 필요가 있다.
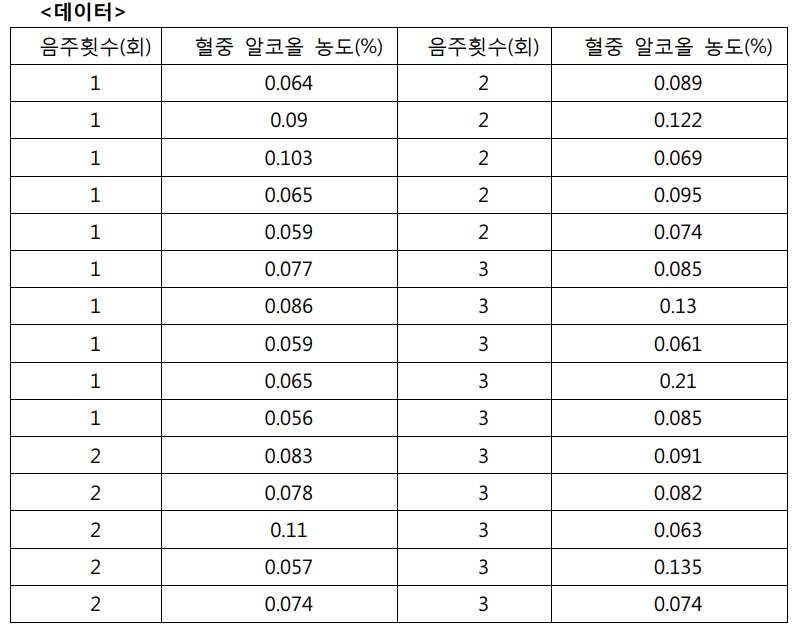
아래의 <표 4-1>은 기술통계량으로서 음주운전횟수 1,2,3별 표본 개수, 평균, 표준 편차, 평균에 대한 95% 신뢰 구간 등의 정보를 알 수 있다.
<표 4-2>는 분산의 동질성에 대한 검정으로서 유의 수준 P = 0.028 < 0.10 이므로, 각 집단의 분산이 동일하다는 귀무가설을 기각해야 한다. 즉, 각 집단의 분산이 동일하지 않으므로 현재의 자료가 분산 분석을 하는 데 통계적으로 문제가 있다는 것을 의미한다.

<표 4-3>은 음주운전횟수에 따른 알코올농도의 차이에 대한 분산 분석 결과이 다. 집단 간의 차이를 검정하는 F 검정 통계량의 유의수준 P = 0.112 > 0.10 이므 로 귀무가설을 채택할 수 있다. 즉, 음주운전횟수에 따른 알코올농도는 통계적으 로 차이가 없다고 할 수 있어, 음주운전횟수가 많은 운전자에게 가중처벌을 할 수 없다. 그러나, 위의 <표 4-2>에서 보는 바와 같이, 분산의 동질성 검정 결과, 각 집단의 분산이 동일하지 않아, 분산분석 자체의 시행이 무의미하다.

<결론>
분산분석이 유용하기 위해서는 표본이 무작위적으로 추출되었으며, 모집단은 동일한 분산을 가지고 있다는 가정을 충족시켜야 한다. 현재의 분석하고 있는 자 료가 이러한 가정을 충족시키는지를 알아보기 위해 Levene 통계량을 사용하였다.
Levene 통계량의 유의확률이 0.10보다 클수록(P>0.1) 모집단의 분산이 동일하다는 귀무가설이 채택된다. 그러나 문제 4의 데이터의 경우, 유의확률이 0.1보다 작아 자료를 이용하지 않는 것이 좋다. 따라서 데이터가 분산분석을 행하기에, <그림 4-1>과 같이 유의미한 비교결과가 있는 듯 보이더라도 분산분석결과는 차이가 없다고 나오는 등, 이는 통계적으로 무의미하므로 유의미한 분산분석을 위해서는 데이터 수집을 다시 하여야 한다.

- 상관분석을 이용한 검정 -
<문제의 소재>
문제 4의 데이터를 음주운전횟수에 따라 세 집단으로 나누어, 분산분석을 통 해 각각의 평균이 동일한지 여부를 판단하려 했으나, 위의 분산분석 결과 각 집단의 분산의 동질성이 동일하지 않아 분산분석을 할 수 없었다.
그러나 <그림 4- 1>에서 보는 바와 같이 두 변수간의 상관관계가 있을 것으로 예상되어, 상관분석 을 통해 그 상관관계를 알아보고, 그 관계가 있다면 회귀분석으로 독립변수(음주 운전횟수)가 종속변수(혈중알코올농도)에 미치는 영향을 예측하고자 한다.
<검정의 원리>
상관분석
상관분석은 연구목적에 해당하는 변수의 관계를 중심적으로 살펴보는 것이므 로, 다른 변수에 의해서 생겨난 관련성을 확인할 수는 없다. 문제 4에서 주어진 데이터로, 음주운전횟수가 증가할수록 혈중알코올농도가 높아진다는 문제를 검정하기 위해서 두 변수의 상관관계를 알아본다.
하지만 혈중알코올농도가 높은 자가 실제로 음주운전횟수가 많기 때문인지 그 여부는 밝혀내기 힘들다. 따라서 상관분석을 할 때에는 연구하고자 하는 목적에 정확한 변수를 설정하는 것이 바람직하다. 또한 상관분석은 두 변수간의 관련된 정도나 방향만을 의미하는 것이지 어떤 변수가 영향을 주는가에 대한 인과관계를 보여주지 못한다.
변수의 관계란 그 관련성의 정도와 방향을 의미하는데, Pearson의 R과 같은 상관계수에 의해서 판단할 수 있다. 상관계수의 해석은 관련 정도를 알아보기 위해서는 절대값으로 표현되는 수치를 보면 되고, 방향은 수치의 부호(+,-)를 가 지고 해석한다.
<문제의 해결>
표 4-4는 기술통계표로서, 음주횟수의 경우 각각 1, 2, 3회인 경우를 10개의 Case를 수집한 것이므로 평균은 2가 되고, 알코올 농도는 평균 0.0864로 나타났다.
표 4-5의 상관계수는 대각선 방향으로 대칭이 같게 구성되어 있는데, 어느 한쪽 방향의 계수만을 확인하면 된다. 첫 번째 줄의 두 번째 칸을 보면 두 변수간의 관계에 대한 Pearson 상관계수와 유의확률, N(빈도)이 나와있다.
음주운전횟수와 혈중알코올농도 간의 상관관계계수는 0.386으로 약간의 관련성(0.2~0.39)을 가진다 고 할 수 있다. 또한 유의확률 값을 보면 0.035로 유의수준 10%에서 볼 때 두 변수간의 상관관계가 유의미한 관계라는 것을 알 수 있다.
다시 말하면, 약간의 관련성을 가지고 있으며, 이 관계는 통계적으로 의미가 있는 것이라고 할 수 있다.
따라서 음주운전횟수가 많을수록 혈중알코올농도가 높다고 할 수 있으므로, 음주운전횟수가 많은 위반자들을 가중처벌을 하려는 도로교통법 개정법에 근거가 된다.

- 회귀분석을 이용한 검정 -
<문제의 소재>
회귀분석은 독립변수(음주운전횟수)가 종속변수(혈중알코올농도)에 미치는 영향력이 얼마나 되는가를 알아보기 위해 사용한다. 회귀분석의 경우 회귀분석을 위 한 가정을 지켜야 한다. 특히, 종속변수와 독립변수가 모두 연속형의 변수이어야 한다.
더미(Dummy) 변수를 사용하는 등의 특별한 경우가 아니면 반드시 지켜야 한다. 문제 4의 경우, 종속변수인 혈중알코올농도는 연속형의 변수이고, 독립변수인 음주운전횟수는 더미(Dummy) 변수보다는 등간 척도에 가까우며, 이 둘간의 관계가 직선의 관계를 가지므로 회귀분석이 가능할 것으로 가정하였다.
<문제의 해결>
다음의 표는 모형의 설명력을 나타내는 표인데, R 제곱 값을 통해서 이 회귀모 형이 전체 자료를 얼마나 잘 설명하고 있는가를 보여준다. 문제 4에서 R 제곱 값 은 0.149로서 실제로 조사된 관측값을 현재의 이 모형은 14.9%정도 설명하고 있 다는 것이다. 회귀직선은 실제 관측값에서 가상으로 계산된 모형이므로 그 모형 자체가 관측값을 얼마나 대변하고 있는가를 알 수 있는 것이다. 현재의 R 제곱값은 높지 않은 값으로, 실제 조사된 관측값을 잘 설명하고 있지는 못하다고 할 수 있다.

다음으로 회귀모형이 통계적으로 적합한지에 대한 검정을 하는 것으로 ANOVA 분석을 하여 그 결과가 유의미하면 적합하다고 판단한다. 여기에서는 F값이 4.902 이고 P값(sig값이 0.035)이 0.1보다 낮기 때문에 이 회귀모형이 적합하다고 판단하 여 그대로 사용할 수 있다.

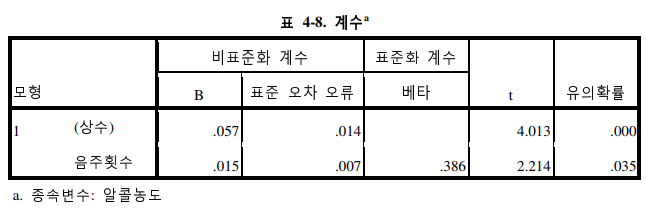
마지막으로 회귀계수와 상수값을 표시하고 있는데, 이를 식으로 표현하면 다음과 같다.
혈중알코올농도(Y) = 0.057 + 0.015 * 음주운전횟수(X)
<결론>
혈중알코올농도는 음주운전횟수가 1회씩 증가할 때 0.015(%)씩 증가한다고 해석하면 된다.
따라서 위의 회귀분석 결과가 음주운전횟수가 많은 위반자를 가중처벌하는 도로교통법 개정안의 근거가 될 수는 있으나, 회귀분석 식이 조사된 관측값을 잘 설명하고 있지 못하므로 그 타당성이 문제될 수 있다.
'경찰학(警察學)' 카테고리의 다른 글
| 범죄자 프로파일링의 개념 (0) | 2019.04.19 |
|---|---|
| [교통안전규제론] 사례 해결 - 3 (0) | 2019.04.09 |
| [교통안전규제론] 사례 해결 - 2 (0) | 2019.04.09 |
| 경찰실무종합(2018년 경찰공제회) - 각론 두문자 (1) | 2019.04.02 |
| 경찰실무종합(2018년 경찰공제회) - 총론 두문자 (1) | 2019.04.02 |
